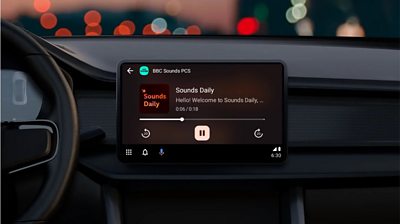



The front door closes and you walk towards your vehicle. Opening the door and settling in for another journey, you place your phone in its cradle. You think of today’s to-do list, the groceries, the journey to see family or friends. You tap Sounds Daily to be greeted by a friendly, but not quite human voice welcoming you to “The best of �������� Sounds - made just for you”.
The voice introduces a few programmes - some old favourites and some new unfamiliar shows. You trust Sounds Daily will choose programmes you love, in an order you’ll enjoy. If the selection is not quite right, you know you can easily skip or you refresh the whole stream with a completely new selection of programmes.
It is all done for you with no need to swipe or search for what to listen to first thing in the morning.
Over the last 9 months, �������� Research & Development’s Sound Lab team have been focussing on the idea of a personalised curated stream of audio content for in-car journeys like this.
Sound Lab is one of our Innovation Labs, bridging the gap between �������� R&D and �������� Sounds. The innovation agenda for Sound Lab puts flexible media capabilities front and centre, seeking opportunities against �������� Sounds current goals and working together on tooling and audience experiences.
Work on in-car experiences is not new to the ��������, there's been significant research into audience behaviour in the car. From the 1990s when R&D were developing DAB (Digital Audio Broadcasting), to R&D's work prototyping for voice UI in 2016 and recently R&D focussed on exploring flexible content and data points that could create highly personalised experiences while driving. These could include highlighting issues with the car (low fuel) or flagging imminent appointments from your calendar. This work used a new method of participatory research, including people panels, which gave us insight into audience actions and interactions in the car. We used this work, plus the ��������'s audience research as a platform to think how might we bring these experiences and insights closer to where we are now with current technology and �������� systems for a near term solution.
Sounds Daily aims to tackle R&D's ambitious goal of giving flexible segmented and personalised content to users on their journey. Sound Lab was the perfect place to look at these opportunities since �������� Sounds is the place for in car entertainment from the ��������.

So what is Sounds Daily? It's a personalised content stream that reorganises short & long form content for each listener at scale, based on their listening habits, while in the car and on the move.
It uses generative AI to query metadata and create scripts that introduce content and signpost what is coming up.
We know the morning commute is still a key part of the daily use of the car and that average journeys in the UK last 16 minutes. That's not much time for a personalised experiment. We started with the morning commute as traditionally, that is consistently the peak listening part of the day. It's when most people head to work, drop the kids off at school or generally start their day on the move. During this time, we wanted to understand if we were meeting the needs of our audience in the era of streaming and the changing world of connected cars where there are considerably more options to choose from than the built-in DAB radio. Now there are many more screens and apps vying for our attention, and the prominence of your brand or app within the car entertainment system will inevitably dictate your success. Our ambition for the project was to make a distraction-free, one-click, personalised listening experience that understands what your listening habits are and serve you the right content, at the right moment, similar to turning on your favourite radio station. This understandably required a flexible media approach rearranging content depending on what you want at the time.
As a way of connecting the content, we looked at the use of generative AI and synthetic media. Presenting thousands, if not millions, of pieces of content together, personalised for every individual user of the stream, at scale, is not possible for a human. This was an exercise to see how audiences reacted and interacted with synthetic media and aggregated and summarised scripts to seamlessly join content instead of a podcast clip and a news bulletin jarring together, for example. Our approach used GPT4, with guardrails around �������� metadata and other IP, to generate scripts and segues, introducing the personalised stream. More about this in our upcoming blog focussed on the technical parameters.

For this experiment, we focussed on a person driving on their own in the car. We all know the concessions we make to our listening habits when travelling in a car with friends and family, so for this experiment, we concentrated on the individual use.
We built this experiment in the Sounds Sandbox; a mirrored copy of �������� Sounds, only it's set apart from the live product. This allows us to experiment freely while not interfering with the current live state that's used daily by millions of people. It also means audiences see the experiments in the known surroundings of �������� Sounds, making it easier to navigate.
The aim was to understand if audiences want a personalised stream that plays out what they want at the time they want it. While testing this, we also thought about how to get the user the best possible stream that matches their tastes in that moment, the type of content (topic as well as type: Cricket as well as Sport) or type of journey. An example might be that on Mondays I don't want to start my day with the news, but on Tuesdays I do.
Before the trial, we asked participants to complete a survey to give us more information about what topics of content they liked to listen to. We also had access to 6 months of their listening data from �������� Sounds to understand their habits. This information helped us to form a baseline to test the stream against each person, every time they used the experience. We integrated tools from teams across the ��������, such as R&D's flexible media tool StoryFormer or �������� Sounds' universal recommendations engine. This was more efficient, but it also means Sounds Daily takes advantage of already established �������� systems. This is something often disregarded in experimentation of this nature, as it can mean slowing down the experiment. For Sound Lab, we want to bring experiments as close to normal workflows as possible so that the route to adoption can be made easier.
The project leaned on a multi skilled team that adjusted when skills were required from editorial, producers, researchers, developers and UX designers. We were able to use the knowledge and expertise of those working directly on �������� Sounds for advice and problem solving when needed, but also get invaluable insight into audience interactions and editorial workflows.
Sounds Daily was trialled with 80 participants over 3 weeks in-car on the morning commute, earlier this year. Learn more about the experience, what we learnt from editorial workflows and tooling, and not least, the insights from our trial participants in the forthcoming parts of this blog series.