
As part of our continuing work on what a Cloud-Fit Production Architecture might look like, we've been investigating how to ingest real media files into the object store at the heart of our system. We've built a file ingest service that breaks files down into small objects and inserts them into the store. We've talked about the store (codenamed "Squirrel") before, but this is its first test with real content.

The premise of our Cloud-fit Production Architecture is to break media into very small objects, such as a frame of video or a frame's worth of audio. These objects are stored by default in an object store. Other components of our system use the store (and references to objects within it) to move, manage and transform media.
Our system is and so each component has a strong API defining its interactions. Using these APIs complex workflows can be composed from simple building blocks. For now the Squirrel Media Store and Magpie File Ingest Service are the only components that exist, but building Magpie was a chance to test out more of our concept.
Magpie File Ingest Service Architecture
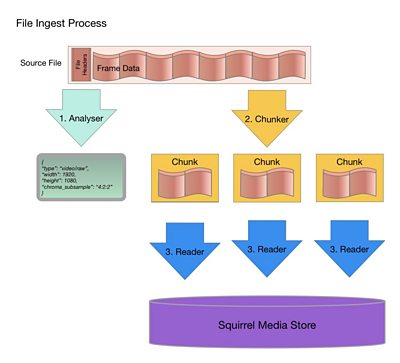
The basic process of ingesting a media file starts by identifying what kind of content it contains: is it video, audio, coded or raw? And using that to generate a list of NMOS-style Flows (see the diagram below).
After that the file is split into chunks of approximately 100MB, and spread across a fleet of workers to be read into the object store in parallel. Splitting the file adds some overhead and extra complexity, but allows the process to be parallelised, which our previous testing has shown is the best way to get cost-effective performance from cloud computing.
-
Flows: Sequences of video, audio or data that could be sent down a wire, such as the pictures from your computer to your screen.
Sources: A group of Flows that are, in principle, the same content. For example, all the different quality settings of an episode of Doctor Who on iPlayer.
Grains: Single elements within a flow, such as video frames.
These all come from the .
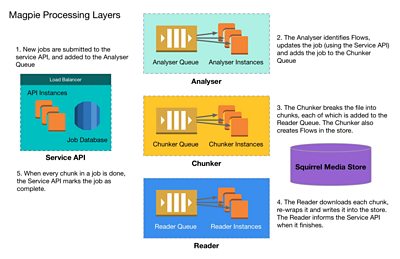
The architecture of Magpie reflects this process, in that it is divided into processing "layers"; the Analyser, Chunker and Reader, along with the Service API for job management.
Each layer is de-coupled from the others and a is used to "feed" work to each of the processing layers, with the Service API providing a feedback path to update job status. Layers can be scaled and managed independently, and jobs can be worked on by any worker at a given layer to make best use of available resources.
The architecture of Magpie reflects this process, in that it is divided into processing "layers"; the Analyser, Chunker and Reader, along with the Service API for job management.
Each layer is de-coupled from the others and a is used to "feed" work to each of the processing layers, with the Service API providing a feedback path to update job status. Layers can be scaled and managed independently, and jobs can be worked on by any worker at a given layer to make best use of available resources.
- When a new ingest job is created, the Service API receives a request from the client containing the URL to download the file, the file MIME type, and what to ingest. It assigns a unique ID to the job, stores it in a database and inserts an entry in the Analysis Queue.
- One of the Analyser workers picks the job up off the queue, downloads part of the file and parses the metadata to identify the Flows within. Results are POSTed back to the Service API and the job is updated. An entry is inserted into the Chunker Queue.
- One of the Chunker workers picks the job up and downloads enough of the file to identify suitable boundaries to split the file into chunks. For each chunk it inserts an entry into the Reader Queue listing the target flows and bytes to ingest. The Chunker also uses the store API to generate placeholder Flows, ready for Grains to be written to.
- One of the Reader workers picks each chunk up off the queue, downloads the relevant part of the file, wraps it into the store's native format (Grain Sequence Format, or GSF, see below), uploads it to the object store and submits metadata. Finally the Reader worker marks that part of the file as done by making a request to the Service API.
- When the last chunk has been read and marked as done by the Reader, the Service API updates the whole job status.
In reality it's a little more complicated than that; there are a lot of different media file container formats, not to mention the huge number of video and audio formats and codecs for various applications. This is part of the reason that ingest jobs require a file MIME type; it allows Magpie to select which implementation of each processing layer to use and which parts of the file to download. However for now, only our own experimental Grain Sequence Format (GSF) file format is supported (we're working on more)...
Grain Sequence Format (GSF)
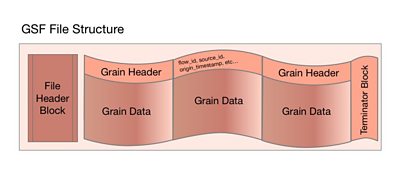
Internally the store uses a simple media file format that was defined as part of our IP Studio work, Grain Sequence Format (GSF).
The main aim behind GSF is making a file format for raw media that is very easy to encode and decode. GSF files consist of a short header section giving the version of the format used, followed by a block for each grain. Each grain block has a header giving its Source and Flow IDs, position in the timeline and metadata, followed by the samples that it contains. Source and Flow IDs are repeated in every Grain and very few constraints are placed on the ordering or content of Grains.
Inside the object store, each object is a GSF file containing one Grain from one Flow, so it made sense to use GSF as the starting point to build Magpie. A working GSF encoder and decoder implementation can be found in our open-source .
Testing
Having built Magpie, we did some testing to ingest content into the store, retrieve a small "time-window" of that content and play it back in a desktop media player. We recorded a 60-second clip of a camera pointed out of our office window (nicknamed "tram-cam" since it points at the MediaCityUK tram stop) and ingested it using Magpie.
Then we wrote a script to request the objects for a 10-second part of that clip from Squirrel and concatenate them into a single GSF file. Finally another script used the open-source to wrap the raw video data into a .MOV container to play it back. Not a very exciting demo, but it proves that Magpie and Squirrel work!
Inside the object store, each object is a GSF file containing one Grain from one Flow, so it made sense to use GSF as the starting point to build Magpie. A working GSF encoder and decoder implementation can be found in our open-source .
-
R&D GitHub
Testing
Having built Magpie, we did some testing to ingest content into the store, retrieve a small "time-window" of that content and play it back in a desktop media player. We recorded a 60-second clip of a camera pointed out of our office window (nicknamed "tram-cam" since it points at the MediaCityUK tram stop) and ingested it using Magpie.
Then we wrote a script to request the objects for a 10-second part of that clip from Squirrel and concatenate them into a single GSF file. Finally another script used the open-source to wrap the raw video data into a .MOV container to play it back. Not a very exciting demo, but it proves that Magpie and Squirrel work!
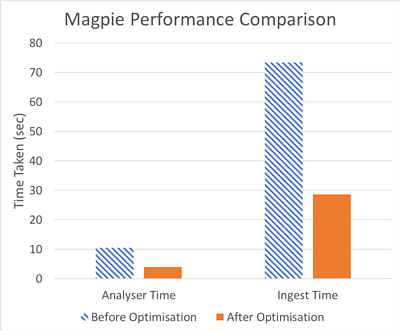
We also carried out more extensive testing to work out what affected Magpie's performance. We found that most of the time taken by an ingest job was making small requests to our S3 object store implementation and waiting for the responses. This matches up with the results of our original S3 testing work.
Under the hood, Magpie uses the Python library to make a file served over HTTP appear as a Python object. httpio includes a "blocksize" parameter which allows larger blocks to be requested in the background when reading files, and later reads will use these cached blocks if possible. We managed to improve Analyser and Chunker performance by approximately ~30% by tuning the blocksize to balance requesting data we didn't need against making lots of small requests.
For the Reader, the main bottleneck was writing objects into the Squirrel object store bucket. Unfortunately we can't just make the objects bigger, they have to be fairly small by design. Instead we added more parallelisation by running multiple copies of the Reader on each EC2 compute instance, which improved performance by around 60%.
What next?
Now that we've proved Magpie works with raw video in GSF files, we're hard at work adding more functionality. To start with, that means adding support for ingesting .MOV files and compressed audio and video; initially H.264 and AAC due to their popularity online and on mobile. We're going to make more use of PyAV and the which should mean we can take advantage of the long list of formats .
We're also going to build on our IP Studio work to demonstrate ingesting raw HD streams (which run at 1.5Gb/s) into a Squirrel Media Store instance. Sending that much data across the public Internet is not practical, so we'll test out our on-premise / based object store, using a approach to store objects on-premise and metadata in AWS.
Finally, we said we wanted to open-source as much of our work as possible, and we're hoping to announce the first part of that towards the beginning of 2019; watch this space!
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section