Own It, the app: Six technical challenges

Jon Howard
Executive Product Manager
Young people now receive their first connected smartphone between the ages of 8 and 12. They may have used a shared device up to that point, but now, in their hands is their first personal carry-everywhere device.
The internet is a force for good; however it hasn't been designed specifically for children. With their own smartphone, young people now have access to a glittering array of experiences which they will explore more freely than they would on a shared device. The Own It app is designed to support and guide children as they make that journey.

Own It consists of a custom keyboard and companion application. The keyboard features technology and machine learning that can assess, intervene and provide help for areas including bullying, hate, toxicity, data privacy and emotions. Once installed, the Own It keyboard becomes the default for all text input fields, covering apps and web applications. This allows the system to provide in-the-moment support, in many cases, before a message is sent – encouraging children to stop and think before they share.
The Own It companion app allows the user to see how they are using their device alongside being able to keep a diary of their feelings. Content is presented that aids children in understanding the available insights and guides them to develop resilient behaviours.
The Own It app was a complex product to develop with many technical challenges to overcome. What follows is a whistle-stop tour through six of the key ones:
1: Providing live feedback within a keyboard
A major feature of Own It is that the keyboard can provide the right support at the right time. To enable this we needed the text to be analysed as it is being typed. A text analysis module, powered by machine learning models, assesses the text for hate, toxicity, emotions, privacy data and a series of safeguarding issues. The system will instantly respond with an intervention where necessary and will also keep the user informed on the emotion sentiment of the message.
When children are in human social situations, they may step over an adult imposed red-line or social norm – but they will, usually, quickly realise that there is a problem because they can see reactions on the faces of the adults or their peers. Once the issue is identified, the child can adjust their behaviour to quickly fit into the norm for the situation. When engaging in online activities, there is little in the way of visual cues, red lines can be crossed in terms of behaviour and the user may not realise until much later. The Own It keyboard is seeking to fix this via the means of a feedback mechanism. By putting a face on the keyboard, the user can see how the message may be received. The face will display how the recipient may interpret the message – this nudges the sender to think about the tone of the message and consider adjusting it to something more palatable.
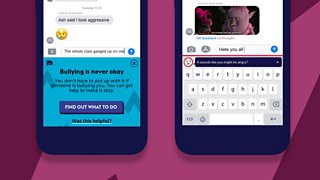
The face takes a feed from an emotion sentiment classifier that has been developed for this task. The classifications have been derived from the Warwick-Edinburgh Mental Wellbeing Scale, a measurement method that has underpinned much of the project design.
When issues with hate or toxicity, privacy or safeguarding are determined, the keyboard will present a related intervention. This is displayed in one of two forms.
A passive intervention will give the child information but without interrupting the flow of input – for example, “Are you sure you should be sharing your phone number?” – We don’t know who the recipient of the message is going to be, so raising the question to the child, allows them to think and judge if it is the right course of action.
A full intervention covers the keyboard entirely. The user is forced to acknowledge the issue by either dismissing the intervention or finding out further information. Own It will never stop a message from being sent, it just seeks to ensure the child is supported as fully as possible.
2: On-device encapsulation
During the discovery phase of the project, we built a proof-of-concept text analyser. This allowed us to begin to experience, measure and comprehend how real-time analysis could work. For the first prototype, a cloud-based solution was implemented - 3.5 GB of machine learning models and word-embeddings hosted on a server. For both data security and speed of response reasons, we wanted to move all text analysis to function entirely on the users’ device.
It seemed like a stretch, but it was essential to explore whether we could achieve the objective of miniaturising the model ensemble to the extent required. An iteration of our proof of concept applied FastText compression to the text classification, producing a first on-device build that totalled less than 40mb, only 1% of the original size. Some accuracy was lost with the models, but we had proved that a serviceable model ensemble could be placed onto a smartphone to achieve the product aspirations.
When moving to production, different compression methods were applied to the models that allowed the size to be reduced to less than 20mb. Further work on the datasets and model design meant that the final f1, recall and precision scores were better than the results from our original 3.5 GB model set.
A key element that enabled the process was to establish a workflow that enabled the model ensemble to be constructed and then ported to both Android and iOS. On-device machine learning is still in its infancy, certainly in terms of natural language processing – however, a route was found using a Keras CNN base model. The Keras model can be transformed to function with CoreML on iOS and with Tensorflow Lite on Android. Developing and testing on the single Keras model reduced the amount of resource required to ensure the efficacy of the system, as well as providing parity between the platform experiences.
3: Ensuring the quality of feedback
The data sets used to train the machine learning models - for hate, toxicity and emotion sentiment - consisted of full sentences. The sort a person would send in a message or put into a note. However, when a user is on a device, inputting text, the sentences don't just appear whole - they are typed in sequentially. This is problematic for a system that is making a prediction on an input, when that input is incrementally changing.
The initial builds and prototypes of Own It provided an experience that showed a confused emotion sentiment feedback mechanism, certainly when the early part of a sentence was being typed. We needed a method to neutralise those first few entered words of a sentence while they were being entered, only engaging the text analysis when there was enough context to make a reasonable prediction on the emotion sentiment. Word or character count was a far too simplistic method, giving poor results. Analysis of the grammatical construct of sentences was a step too far - certainly for a project that already had many complex moving parts.
The implemented solution to this problem was surprisingly simple but provided a significant improvement to the user perception of the issue. 1/2 million messages, mostly from young people were analysed and a collection was made of the most common 'sentence starts'. That is, words that are present in a sentence before the object, subject or other context is imparted. For example:
- What was the...
- Can I have a…
- Thank you for your…
The list was filtered down to contain only the most common ‘starts’, eventually totalling less than 2000. When a user types a message that matches or partially matches anything in the list, the text isn't analysed and therefore the visual feedback is neutral. Because the list only contains partial sentences, the text analysis and related responses kick in as soon as the emerging sentence begins to have meaning. This function reduced the occurrence of early and uninformed analysis by an amount that has all but taken the problem off the table. While restricting variances in sentiment response early in most sentences, the system still allows short or uncommon sentences to be analysed and responded to. The user experience is much more consistent, allowing trust to grow in the asserted feedback on display.
4: Restricting the occurrence of bias within results
All data contains bias – much of the training data for Own It came from human sources, so the biases are innate. The challenge for Own It was to counter the bias, both in the training sets and by using pre-processing methods, so that the outcomes are as unaffected as possible.
One area of potential bias came up with the emotion sentiment classification, where the displayed representation is a facial reaction to the emotion of the message. There was a worry that protected characteristics, such as race, gender and religion could have a possibility of affecting the results and provide responses that could cause offence (a misplaced angry or frightened face). As the key function of the emotion sentiment classifier is to determine only the emotion of a given sentence, the presence of any protected characteristic should not affect that response. With this taken as a rule, we needed to remove the protected words before analysis – without affecting the construct of the sentence. A ‘Bias Neutraliser’ list was drawn up containing the characteristics and grammatical variations.

This Bias Neutraliser list is parsed when the message is being pre-processed ahead of submission to the text analysis models. If a word or phrase matches the list, then it is neutralised within the sentence. To retain the sentence structure, the matched word is replaced with a neutral word – in the implementation, literally the word “neutral”. So, “the Christian walked down the stairs” is passed through the analysis as “the neutral walked down the stairs”. In this case, the word ‘Christian’ is given no opportunity to influence the emotion sentiment results.
The implemented Bias Neutraliser pre-processing affects only the system responses and provides a layer of support for the emotion sentiment analysis, allowing it to focus on its core purpose.
5: Developing Children's focussed keyboard
When trying to make a keyboard that is to be used by children – it isn’t just all of the basic elements that need to be in place, they each need to be developed with a young audience in mind. Autocorrect, autocomplete and next-word prediction must perform to a high standard AND be relevant for the users.
To support these core keyboard functions, we developed a children’s dictionary. An analysis of messages written by young people produced a word density map of the most used words and their frequency of use. The result was compared to a standard adult-focussed list and merged to create a core system dictionary that ensured the broadest range of users could benefit.
With improvements driven by words commonly used by young people, there was still an omission related to the uptake of new online language by young audiences who engage with the plethora of available platforms. New words and phrases emerge and are used within messaging on specific platforms, a growing expansion of the lexicon driven by new technology and its users. Whether it is yeet, thicc, poggers or oomfs (look them up - the etymology of the chat speak area is a fascinating story, one not for this blog, however.). The Own It keyboard is designed to work on all media platforms seeking to make the experiences as friction-free as possible. For this to work well, the functions need to be cognizant of these new words. A review of this ‘chat-speak’ allowed us to create a glossary that informed an expansion of the dictionary, giving it a wide enough set if terms for now, but this will be an ongoing journey.
6: Ensuring data privacy
Data privacy within the Own It experience has been a primary objective. It is the reason we have encapsulated the machine learning models onto the device and is also the reason we don't key log any of the data. When a message is typed, it is passed for analysis. Once a user sends or deletes their message - no record of it is stored. A data point is generated for each message sent. This contains just the sentiment of the message and a flag for any interventions types that may have occurred. This data point is placed in a secure data store on the device and can only be accessed by the companion app - the system will analyse these data points, looking for insights which can be presented to the user via support content.
The setup of the Own It system gives the machine learning a closed loop. A user can report false positives. If they receive an intervention, they can report that it was incorrect - by investigating the patterns of these false positives, we can work out where some of the classifiers aren't working as well as expected and put effort into finding and shaping further datasets that can help to improve the accuracy of these models.
Outside of this user feedback loop, the Own It team will be looking to improve the datasets and implement new techniques to increase the accuracy and performance of the full machine learning ensemble.
The advancement and proliferation of AI has created a window of problem-solving capabilities. With these new capabilities, comes a need to act both ethically and with responsibility. Within the Own It product, we have endeavoured to employ machine learning for good and treat personal data as sacrosanct. It is crucial for users to have confidence that the system is there to support them and is worthy of trust. Within the companion app, we have content that describes how Own It works. Written in an easily digestible form, it seeks to add a layer of transparency that will grow trust in Own It and that it is there to provide dedicated help to the individual.
To develop and build the Own It product machine learning and analysis elements, the 主播大秀 worked in partnership with Switzerland-based Privately. Some of Privately's previously developed models were enhanced and encapsulated onto devices, while new models and related technologies were co-developed and implemented. The audience facing elements of Own It were developed and built in partnership with Glasgow’s Chunk Digital.
Own It is now available on the and . It is designed specifically for smartphones. If you have a child who is about to receive their first phone or has recently done so, then get them to install Own It and let us know how you get on.