
Monitoring data for badmington and volleyball during the 2012 Olympics
Twelve months ago, there were three of us in the new Olympic Data Team: product manager Oliver Bartlett, developer David Norris, and I, David Rogers, as technical lead. We were tasked with providing data for the 主播大秀's Olympics 2012 project: stats, events, results...
Today, we are a team of 20, we have built five applications, provide 174 endpoints, manage 50 message queues and support ten separate 主播大秀 Olympic products - from the sport website to the Interactive Video Player.
Over the course of the games, we expect to process over four million messages, such as athlete profiles, diving events from the Aquatic Centre or the latest medal table for Team GB. Throughout the project, there have been two distinct, but closely-linked objectives.
Two Objectives
Firstly, we needed to build a high-throughput, low message processing system, making sure the facts and figures emerging from the Olympic venues were available, throughout the 主播大秀, quickly and accurately.
Secondly, we wanted this data to be part of a wider story, ensuring the wealth of 主播大秀 content, such as news, blogs, galleries, video and live commentary could be seen alongside the live data, and presented to suit a range of audiences. This second objective is best exemplified by the 10,490 athlete pages on the 主播大秀 sport website, each offering a dynamic and meaningful aggregation of content, all based around an individual Olympian.
1: High-throughput message processing Olympic Data
Receiver, Router, API and the Content Store
The feed we receive from our data provider, , is a high-throughput XML feed.
We needed to build a system that was capable of receiving and processing thousands of messages every minute.
We needed to be able to prioritise the messages, so that we process the real-time data before the bulk updates. For example, when the triathalon finishes, we receive a detailed statistical update for every competitior. These messages can wait, what we really need is the result. To ensure we receive the most timely information first, we split all messages into a set of 50 queues, we then tune the processing rate for each queue to make sure we can show the most up-to-date view of the Olympics where it really matters.
2: Connecting content across the 主播大秀
TRiPOD 2012, DSP and the Triple Store
The second objective of the project was to take the data feed and weave it seamlessly into the rest of the 主播大秀 Olympic content, using in our . To achieve this, we have integrated the Olympic data with the 主播大秀's platform - developed for the FIFA World Cup 2010 and . This approach, in the context of the Olympics, can be summarised by the following 3-step process:
- Convert the athlete, world record and podium XML data into RDF and publish this into our OWLIM triple store
- Journalists, and other creators of 主播大秀 content, can now 'tag' articles, blogs, galleries or videos with Olympic athletes, venues, sports, events and teams
- This results in
主播大秀 Olympics Data Service
The resulting system fuses these two objectives into a single service, allowing applications to leverage both the real-time XML data, and the richly interconnected semantic data.
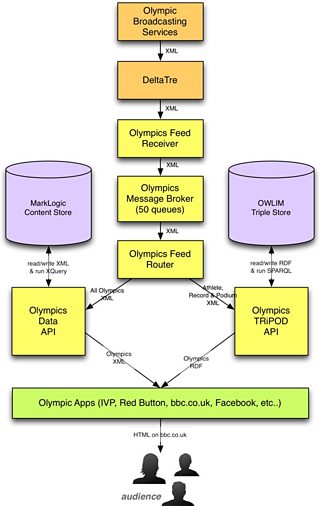
The 主播大秀 Olympic Data Service, showing the high-throughput message processing (left and centre) integrated, using linked data, with content from around the 主播大秀 (right)
The Technical Challenges
Racing the video into the IVP
The Interactive Video Player is the most complex, but in my opinion, most exciting online offering from the 主播大秀 for the 2012 games.
It shows any one of our 24 high-definition video streams, but also provides an interactive panel showing real-time stats about the events taking place in the video. This behaviour represents a significant challenge.
Our AV teams have invested greatly in reducing the latency for our online video output, crucial for live events during an Olympic Games. Unfortunately, the lower the video latency, the less time we have to provide the accompanying stats.
The diagram below shows how we modelled the various latencies, delays and caching layers involved:
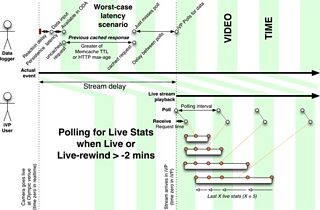
Modelling the dataflow, from the venue to the screen
We explored two competing methods of providing stats to the IVP:
- Obtain stats in discrete blocks of time. e.g. "Stats for the time period 12:10pm->12:20pm" with each time period a different API URL
- Obtain stats from the same API URL, receiving an updated 'last X events' each time
Both methods have been used, the first method for video-on-demand, and the second for live video.
Here, the two methods of obtaining stats are compared.
| Method | Method 1: Blocks of time | Method 2: Latest X stats |
|---|---|---|
| URL | /stats/{datetime} (time period is fixed, so starting time is provided) | /stats/latest |
| Worst-case scenario | Stats are requested before they have been received | Stats are so frequent, that more than X stats occur between each poll |
| Caching | Between 10 seconds and 4 hours, depending on how old the stats are | ~3 seconds |
| Used for | Video-on-demand Live-rewind > 2 mins |
Live video Live-rewind |
The trickiest aspect of this two-method approach is to transition between the two methods.
When watching the IVP, it is possible to 'time-slip' if the connection is poor. If the user drifts back over two minutes, they will shift from method two to method one. We used a technique of 'snapshots' to overcome not just these transitions, but also the times when an audience member moves around the stream, for example, returning to live after watching a goal from 20 minutes ago.
Prior to the games, we did prototype 'push' technologies such as to solve the same problem. Unfortunately, this was too great a technical challenge to solve in time for the games, particularly given our requirement to scale to millions of users.
As the video latency reduces, 'push' will become the only viable option for real-time stats.
Building APIs rapidly within a rich domain
The domain of Olympic sport is both deep and broad.
We have had to deal with schedules, video logging, statistics, athlete meta-data, photos, medal tables and more.
Within each type of data, there is a huge variety according to sport.
For example, football schedules are arranged into two distinct phase: league and knock-out, with each match comprising two teams, where each team is comprised of a squad of players. Events within a match include red cards, fouls, half-time and goals.
By comparison, this is how :
"64 archers compete. The competition begins with the ranking round. Each archer shoots 72 arrows (in six ends, or groups, of 12 arrows). They are then ranked by score to determine their seeding for the single-elimination bracket. After this, final rankings for each archer is determined by the archer's score in the round in which the archer was defeated, with the archers defeated in the first round being ranked 33rd through 64th."
This complexity is represented within the XML, where the the schema for each type of XML we receive can be extremely complex, having to represent varieties between sports, events, and even different phases of the same event.
In addition to this, like most software projects, the requirements were subject to frequent change.
Within this context, we needed to build a system to ingest, process and provide this data.
To achieve this, we adopted two approaches, "light-touch" and "best-effort", and relied on an XML Database:
Light-touch
We chose not to validate or model the content of the XML unless absolutely necessary. For example, take the medal table. If possible, we could receive the XML, identify that it represented a medal table by examining a single element, and from this point onwards, ignore the rest of the contents.
In reality, we needed to verify, route, process or enrich most of the data.
Where this was necessary, we only accessed or manipulated a small proportion of the XML. Using this approach, our data provider could make significant changes to the structure of the XML without any changes to our APIs necessary.
Ultimately, our clients - the systems that created visual representations of the data - would need to use the more complex, domain-specific detail. These clients did not, however, have to wait for us to update our models, schema or validation logic.
Best-effort
Closely associated with the approach above was the idea of 'best-effort' responses. This was the idea that, whatever the circumstance, it was better to delivery some content, within a known timescale, rather than nothing at all. This would leave the client the option to gracefully degrade the user-facing content as they saw fit.
Behind this principle is the knowledge that we will not have many options for updating and re-releasing our systems during the two-week window of the games.
MarkLogic XML database
Fundamental to this approach was the use of MarkLogic to store and retrieve data. MarkLogic is an which uses to store and retrieve data.
Given the timescales, this project would not have been achievable using a SQL database, which would have pushed the design towards more complete modelling of the data.
Using MarkLogic, we could write a complete XML document, and retrieve that document either by reference to its location, a URI, or using XQuery to define criteria about its contents.
For example, all documents matching a particular could be obtained.
Simulating the Olympics
When building a complex software product, the common sense approach is to get the software in front of your customers as soon as you can. We've done this where we could - we had pages-per-athlete, venue and event ready early in the year. We used the Interactive Video Player for Euro 2012 and Wimbledon.
The problem is, without an Olympics Games happening, you have neither realistic data, nor the audience levels, to genuinely put the product to the test.
To get around this problem, we have invested a significant proportion of our efforts to simulate the Olympics. The most obvious manifestation of this was the Olympics Simulator application. This allowed people around the business to set up streams of data which could simulate anything from an athlete registering for the games, live stats for different sports, video logging information or medals being won.
The simple interface provided is shown below.
主播大秀 Olympic Simulator interface
These streams of data could then be synchronised with video to provide a rich and dynamic user experience on bbc.co.uk, or our test environments, without waiting for the Olympics to begin.
There is no dress rehearsal
Whilst simulations, load testing, stress testing and end-to-end testing have built a lot of confidence, we were still facing a 'big-bang' on July 27th when two things happened:
- Millions more people started using the 主播大秀 Olympics website - using features that were not active before the games, such as medal tables, live stats, live logging events and the 'Olympics Live' feed from around the games
- Messages are delivered by DeltaTre in much higher volume
To give ourselves flexibility, we have created a number of 'knobs and levers' to control our applications in production.
These include the following:
- Message flow control: If, for example, the sport of boxing is generating too much statistical data, we could deprioritise these messages in favour of the other sports.
- Caching timeouts: If we discover that an endpoint has become resource intensive, we can raise the caching timeouts to reduce the number of times we need provide data each minute or hour.
- Keyword whitelists: We have decided in advance what log event information we would like to be displayed in different areas of the the site. For example, for football, we want a 'red card' to result in a marked Chapter Point in the video, so our audience can rewind back to this event.
We may discover during the games that the pattern of events is not what we expected; being able to change how we respond to these different events will allow us to fine-tune the user experience in real-time.
Legacy
Creating systems, libraries and techniques that could be used beyond the games was crucial for this project. We wanted this unprecedented investment in the Olympics to have lasting, tangible benefits for the 主播大秀 and its audience.
Here are some of them:
- Data, fit for reuse: A proportion of the data gathered for the games has been published to our linked data platform using the 主播大秀's sport ontology. Although still evolving, this ontology will allow us to continue to integrate future sporting events with the past. Athletes, sports, events and venues will all maintain consistent identifiers, and 主播大秀 content will be associated with these concepts. Ultimately, we hope to provide access to this data publicly, allowing people to build applications with access to the breadth and depth of 主播大秀 content. With the 主播大秀 obtaining the rights for the Olympics up to 2020, we can already start to think about how this data will be useful for Rio 2016!
- Libraries: For this project we have built a set of software libraries for reuse around the 主播大秀. A RESTful API framework produced for this project is already used in the systems that power the 主播大秀 mobile news website, and the football section of the 主播大秀 Sport website.
- Applications: The TRiPOD 2012 API, built to power the Olympics, will live on as the backbone of the 主播大秀 Sport website, showing the competitions, competitors, venues and teams of all the sport covered by the 主播大秀.
- Persistent Stores: The Olympics Data projects have pushed both MarkLogic and OWLIM to their limits and we have discovered better ways of working with these stores. This best practice, often captured in software tools, has been established for future projects.
With the Olympics now underway, we've had a chance to see these approaches used for real. Whilst we have had to make use of our 'real-time controls' to adjust and fine-tune the user experience, I believe we have created something that sets the 主播大秀 apart for this first 'digital Olympics'.
I look forward to reading your comments.
David Rogers is a Senior Techincal Architect, 主播大秀 Future Media, News & Knowledge