How metadata will drive content discovery for the 主播大秀 online

Jonathan Murphy and Jeremy Tarling
Digital Publishing, Design & Engineering
Tagged with:
Jonathan Murphy, editorial lead for metadata and Jeremy Tarling, lead data governance specialist in Digital Publishing, explain what's being done to create a common metadata structure.
The 主播大秀’s online portfolio has been built up over more than 20 years into a rich and varied collection of websites and services - but with all this content, it’s sometimes difficult trying to find some of it, let alone manage it all. As a result we have lots of hidden gems that aren’t being surfaced, and that’s something that we’re trying to fix with a new content discovery strategy.
One of the challenges we’re facing up to as we rebuild our digital portfolio is how to make more of our content discoverable and personalised to more of our audiences. That’s particularly true of the under 35s age group who now have an array of competing platforms which do a great job in building algorithms to attract their attention.
Underpinning this strategy of discovery and personalisation will be establishing more detailed metadata that describes all of our content using the same terminology and the same tools and data model.
Metadata is the background info that describes the things we make. It can come in all forms, from technical metadata such as which camera was used in a film shoot to promotional metadata used to describe the plot of a programme. For the remit of this project, we’re focusing on what we call descriptive content metadata - tags that describe what an asset (e.g. an article, programme or TV/Audio clip) is about or who/what it mentions. That’s already used in areas like the 主播大秀 News and 主播大秀 Sport websites using data architecture called Dynamic Semantic Publishing that was created for the London 2012 Olympics, and now drives many thousands of subject-based aggregations, or Topic pages.
There are also categories of programmes on 主播大秀 Sounds and 主播大秀 iPlayer, which use a mixture of genres and formats contained in the PIPs database that supports our vast online library of programme information. As a result of these two data silos, and their limitations, it’s difficult to offer audiences any pan-主播大秀 experiences or anything that requires an in-depth understanding of the content.
Common Metadata
So we need to go further than that, in order to offer material that covers both the breadth of our online content and to suit everyone’s tastes and needs. Here in the 主播大秀’s Digital Publishing team, we’re developing tools that make content description possible at all stages of production across our portffolio, and new vocabularies that allow for richer descriptions of our content.
We’ve already worked with the Sounds team, who have used our new tags and curations to create some of their Music Playlists which give you a soundtrack to suit your mood, whether that’s ‘chilled out’ ‘feel good’, music to dance to, or music to focus your mind.
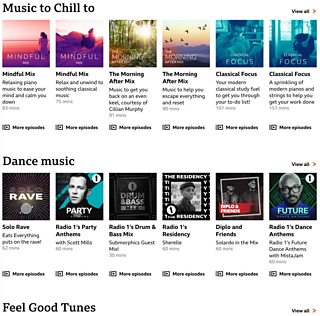
To make this possible we’ve developed a concept that every piece of content has a basic set of common metadata associated with it, that it carries around wherever it’s surfaced across the 主播大秀’s portfolio - whether that’s in Sounds, iPlayer or on the 主播大秀 News homepage. We’re storing this set of basic common metadata in what we call a ‘Passport’, and to create and manage this metadata we’ve developed a tool called Passport Control.
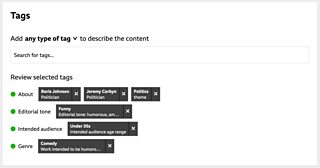
Using the simple graph model first developed for the 主播大秀’s 2012 Olympic’s coverage, we create subject-predicate-object triples to describe the nature of the relationship between an asset (the subject) and a tag (the object).
In the above example this asset has been described as being “about” some things - this kind of subject based tagging is well established at the 主播大秀, especially in our journalism output. But we have added three new predicates: “editorial tone”, “intended audience”, and “genre”.
Each predicate can be used with an associated controlled vocabulary of terms. In some cases these controlled vocabularies are taxonomic hierarchies (like 主播大秀 genres) while in others they are simple lists of terms that we have developed to describe our output in ways that make sense to us and our audience.
These new types of metadata can be used to make much richer collections of content, either as manual editorial curations or algorithmically generated recommendations.
Our colleague Anna McGovern explains further some of those challenges we face at the 主播大秀 here in building our curations and recommendations, building on our public service values. With the amount and variety of material that we produce, from news articles to music mixes, live events to boxsets, we think we’re in a good position to provide content for all kinds of different tastes.
We’ll update you more about metadata developments, curations and recommendations as these features begin to roll out on 主播大秀 Online over the coming months.