Streaming Euro 2020 live at a record new scale

Pierre-Yves Bigourdan
Software Engineering Team Lead
Tagged with:

Summer 2021 offered a rich selection of events to sports enthusiasts: , and the , to name but a few. An ever-increasing proportion of the 主播大秀’s audience has been moving from traditional broadcast to online consumption - the Euro 2020 Final, where Italy played England, set a new record for 主播大秀 iPlayer, with 7.1 million viewers streaming the match online.
In comparison, the 2018 World Cup Quarter Final, where Sweden opposed England, only attracted 3.1 million online viewers, yet our systems at the time became overwhelmed, leading to . Luckily enough, this happened at the very end of the match when the outcome was already settled. However, this incident did not go unnoticed by our engineers and triggered a significant redesign of our workflows.
How did we scale our live streaming architecture to reliably deliver media and allow audience figures to reach new heights?
From pull to push
To answer that question, let’s first review what happened in 2018. Many streaming platforms, including iPlayer at the time, operate with what is commonly described as a pull model. The player on your TV, phone or computer requests the media from a third-party . This forwards the request to the 主播大秀’s routing and caching servers, which in turn send it on to the packager. The role of this last system is to transform encoded media by wrapping the raw video and audio into container files that are suitable for distribution to a variety of client devices.
You can view things as a funnel: multiple layers of caching and routing are present along the way to collapse millions of player requests every second down to a trickle of requests back to the origin media packager, each layer pulling the media from the next layer up. All of this occurs while trying to keep as close to the live time of the event as possible.
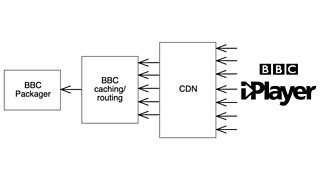
The 2018 pull model. Arrows represent the flow of media requests, from iPlayer on user devices all the way up to the packager.
Even though widely used, this pattern has some significant drawbacks, the best illustration being the major incident that hit the 主播大秀 during the 2018 World Cup quarter-final. Our routing component experienced a temporary wobble which had a knock-on effect and caused the CDN to fail to pull one piece of media content from our packager on time. The CDN increased its request load as part of its retry strategy, making the problem worse, and eventually disabled its internal caches, meaning that instead of collapsing player requests, it started forwarding millions of them directly to our packager. It wasn’t designed to serve several terabits of video data every second and was completely overwhelmed. Although we used more than one CDN, they all connected to the same packager servers, which led to us also being unable to serve the other CDNs. A couple of minutes into extra time, all our streams went down, and angry football fans were cursing the 主播大秀 across the country.
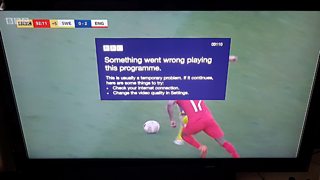
主播大秀 iPlayer outage during the Euro 2018 quarter-final. Photo: Steve Hy
We did fix and mitigate the immediate performance issue. After running several long and deep root cause analysis sessions, we concluded that having our media servers exposed to a request load that was ultimately not in our control was not a safe position to be in.
We decided to re-architect the system by switching from a pull to a push model. The idea is quite simple: produce each piece of media once and publish it to a dedicated live origin storage service per CDN. From where we stand, the CDN acts as a pure ingest point and has no visibility on any of our servers. In other words, we alleviate any risk of the CDN overwhelming our systems: as more people view our streams, the load remains constant. We end up with a much cleaner separation of concerns, with the 主播大秀 accountable for producing all media in time and the CDN now solely responsible for caching it and making it available for download at scale.
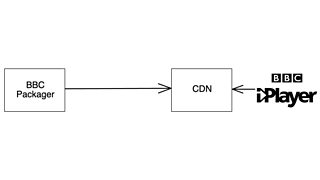
The 2021 push model. 主播大秀 iPlayer on user devices simply downloads media that was previously published to a CDN.
Drilling down on the packager
Before they arrive at our packager, video and audio signals are encoded into formats appropriate for distribution to our audiences. The cloud-based encoder is also responsible for generating an adaptive bitrate set of outputs, in other words, a range of picture and sound qualities to cater for different network speeds and device capabilities.
The resulting encoded media is then sent to the packager. Its role is to prepare all the files which will be requested by devices to play a stream over an HTTP connection. The packager produces two types of streams:
- streams: in our case, the encoded media is packaged in fragmented containers. Apple devices and some older TVs use these.
- streams: in our case, the encoded media is packaged in fragmented containers (MPEG-4 part 12), commonly referred to as fragmented MP4. All other devices use these.
At a high level, the revised workflow is composed of four main components, the repackager, the distributor, the manifest generator, and the conductor:
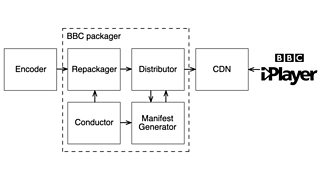
A high-level architecture of the new push packager workflow.
All four components are designed as load-balanced fleets of microservices to support the load of dozens of 主播大秀 streams continuously flowing through them. These streams correspond to all our linear TV channels and their many regional variants, half a dozen World Service streams, and a variable number of event streams. The workflow is run in two independent cloud regions to allow for additional resiliency. Let’s delve into the role of each component.
The repackager
The upstream encoder produces video using and audio using . Both the video and audio are wrapped in TS containers, and the encoder continuously sends small container files which hold roughly 4s of content each. The repackager component receives these chunks of content via HTTP PUT requests. Conveniently, their format is suitable for HLS streaming: to make HLS available, the repackager can simply forward them untouched to the next component in the workflow, the distributor.
However, it additionally needs to transform the TS chunks in a format suitable for our DASH streams. The repackager’s task is to parse the TS container and extract the raw H.264/AAC data. Using information gathered by reading through this media data, it rewraps the pictures and sound in an MP4 container with all required metadata. The generated MP4 files are sent to the distributor alongside their TS counterparts.
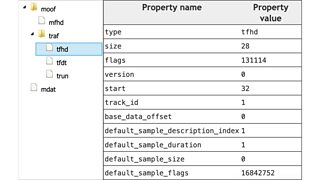
Structured metadata from one of our generated MP4s, displayed in the mp4box.js viewer.
The distributor
The distributor component receives the MP4 and TS chunks sent by the repackager over HTTP, and in turn, publishes them to CDN storage locations so that our audiences can access them. Depending on the stream, one file may be published to several CDN endpoints for additional redundancy. The distributor can essentially be viewed as a one-to-many mapper, handling all authentication and retry behaviour when interacting with a CDN.
Additionally, for every TS chunk it receives, the distributor sends an HTTP request to the manifest generator, triggering the generation of a manifest corresponding to that chunk.
The manifest generator
Manifests are text documents. Their primary goal is to guide the player to download the different media chunks within a given stream. When the play button is pressed, the player first downloads the manifest, and using the information it contains, keeps on requesting small media files containing 4s of content. The downloaded files are rendered one after the other, allowing viewers to have a continuous and seamless playback experience. HLS and DASH define different types of manifests, and the manifest generator component is responsible for creating these variants. Generated manifests are sent to the distributor component over HTTP to be published to the CDN alongside the media chunks.
The conductor
The conductor provides several REST API endpoints to configure the behaviour of the other components in the workflow. For example, it is responsible for driving the automatic scaling of the microservices when additional streams are started, adjusting the monitoring, keeping track of start and end time of events, filtering encoder inputs, and a variety of other management tasks.
Paving the way to the future
Driven by a cross-departmental effort involving several teams, our push packager workflow has been successfully running in production since February 2021. Initially trialled with the 主播大秀 Two HD channel, it now continuously carries over 40 streams, with additional event streams soon to be migrated. Over a million new files are produced every hour, and billions of media chunks have successfully been uploaded to CDN storages since its inception. Across all summer 2021 sporting events, the system allowed us to reach a record 253 million play requests on 主播大秀 iPlayer and 主播大秀 Sport.
Even though the numbers shared here fit well within the realm of hyper-scale when it comes to data produced and network traffic, it is worth noting that online streaming is a small proportion of the 主播大秀’s audience coverage. Linear broadcast TV still makes up the lion’s share. However, online consumption is steadily increasing, reaching about a quarter of all viewers during the summer events, and an IP-only future is fast approaching. With these efforts, we will be better placed to move forward: our new packager gives us the flexibility to adapt our content to take full advantage of improvements in specifications and allows us to reliably and cost-effectively serve millions more online viewers in the coming years.
Want to see our system in action? Open 主播大秀 iPlayer and simply press play on one of our live streams!